
Having read the chapter on counting and per-CPU counters in Paul Mckenney’s recent book, I thought I would do a small experiment to check how good or bad it would be if those per-CPU counters were close to each other in memory.
Paul talks about using one global shared counter for N threads on N CPUs, and the effects it can have on the cache. Each CPU core’s cache in an SMP system will need exclusive rights on a specific cache line of memory, before it can do the write. This means that, at any given time only one CPU can and should do a write to that part of memory.
This is accomplished typically by an invalidate protocol, where each CPU needs to do some inter-processor communication before it can assume it has exclusive access to that cache line, and also read any copies that may still be in some other core’s cache and not in main memory. This is an expensive operation that is to be avoided at all costs!
Then Paul goes about saying, OK- let’s have a per-thread counter, and have each core increment it independently, and when we need a read out, we would grab a lock and add all of the individual counters together. This works great, assuming each per-thread counter is separated by atleast a cache line. That’s guaranteed, when one uses the __thread primitive nicely separating out the memory to reduce cache line sharing effects.
So I decided to flip this around, and have per-thread counters that were closely spaced and do some counting with them. Instead of using __thread, I created an array of counters, each element belonging to some thread. The counters are still separate and not shared, but they may still be in shared cache-line causing the nasty effects we talked about, which I wanted to measure.
My program sets up N counting threads, and assumes its running each of them on a single core on typical multicore system. Various iterations of per-thread counting is done, with the counters separated by increasing powers of 2 each iteration. After each iteration, I stop all threads, add the per-thread counter values and report the result.
Below are the results of running the program on 3 different SMP systems (2 threads on 2 CPUs, sorry I don’t have better multi-core hardware ATM):
Effect of running on a reference ARM dual-core Cortex-A9 system:
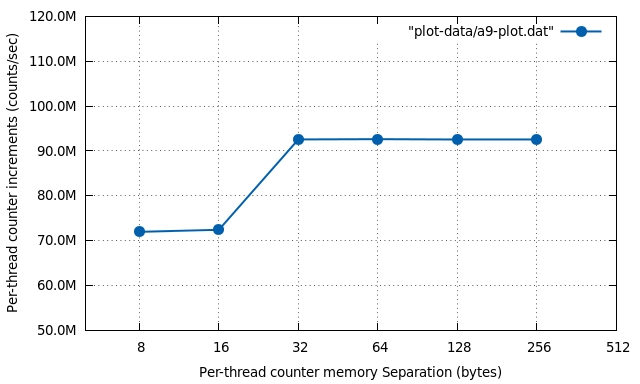
Notice the jump in through-put once the separation changes from 16 to 32 bytes. That gives us a good idea that the L1 cache line size on Cortex-A9 systems is 32 bytes (8 words). Something the author didn’t know for sure in advance (I initially thought it was 64-bytes).
Effect of running on a reference ARM dual-core Cortex-A15 system:
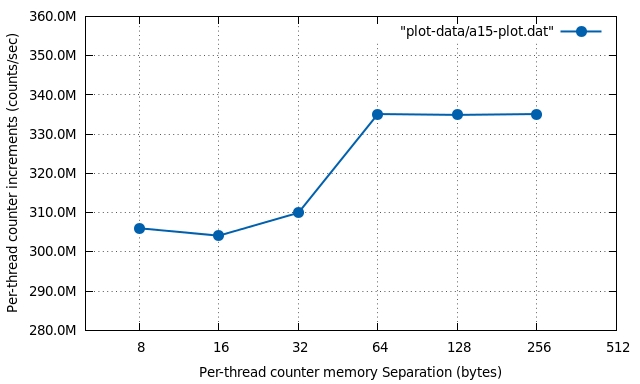
L1 Cache-line size of Cortex A-15 is 64 bytes (8 words). Expected jump for a separation of 64 bytes.
Effect of running on a x86-64 i7-3687U dual-core CPU:
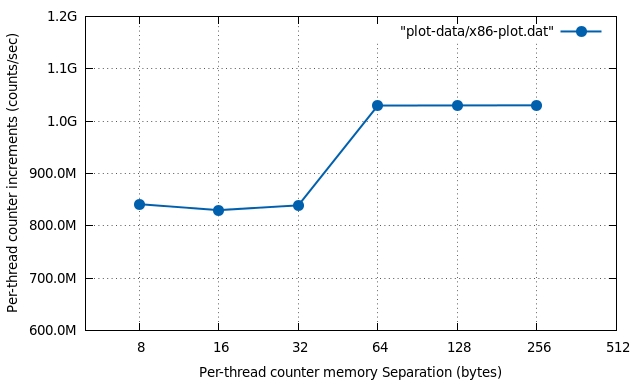 .
.
L1 Cache-line size of this CPU is 64 bytes too (8 words). Expected jump for a separation of 64 bytes.
This shows your parallel programs need to take care of cache-line alignment to avoid false-sharing effects. Also, doing something like this in your program is an indirect way to find out what the cache-line size is for your CPU, or a direct way to get fired, whichever way you want to look at it. ;)